
Capstone Project

1. Background
We’ve all done our shopping online. From electronics, to household items, and even pantry items. I would believe that it would be safe to say that many of us are well versed buying online from websites, both local and foreign.
Every time we go looking for something, there are seems to be a variety of what you are looking for. How does one decide which item to buy, since item A and B do the same thing, and are at the same price?
We no longer make our purchasing decisions in the blind. We rely on product reviews. Any shopper reads approximately 10 reviews before deciding if they would buy it. A review is a testimony. It’s a proven track record of the product by previous buyer’s recommendations or warnings.
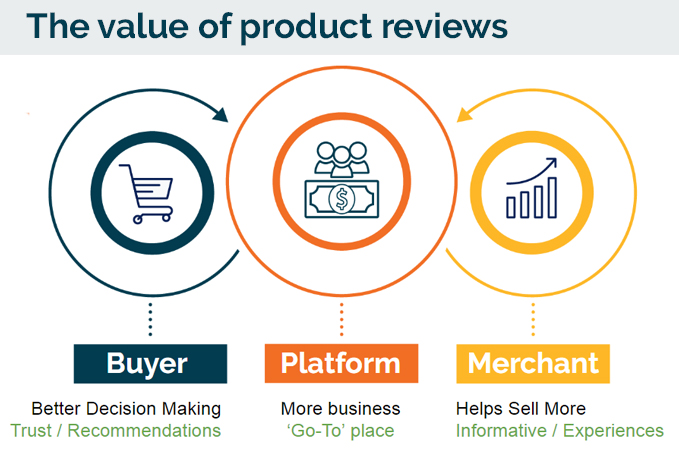
The value that product reviews bring on any e-commerce platform:
- For the buyer: Better decision making. Merchant/Product trust. Recommended.
- For the merchant: Helps sell more. Better credibility. Informative experience.
- For the platform: More business and traction. Platform becomes the ‘Go-to’ place for shoppers.
- Adds to the customer experience
Many products receive reviews both good and bad. However it is the ‘Helpful’ reviews that are the decision influencing factors.
1.1. Understanding Reviews
Reviews are often separated into 2 groups. Helpful or Unhelpful. Helpful reviews help buyers decide if they should purchase. Reviews also show the shared experiences from a previous buyer. Unhelpful reviews, on the other hand, have little or no relevance to decision making, infact they often ignored.
Most e-commerce platforms allow the reviews to be voted on.
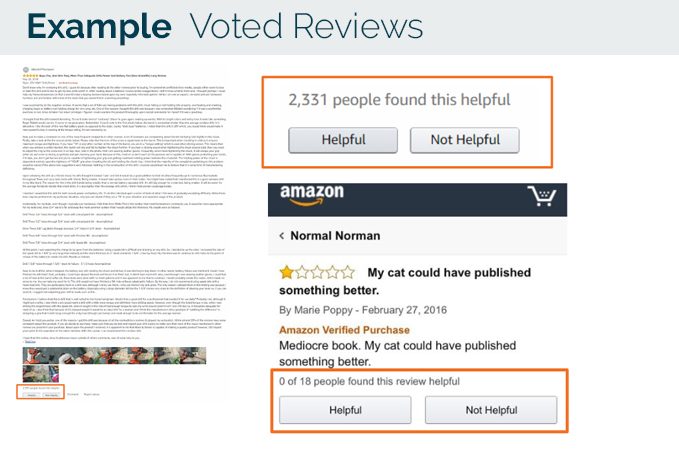
2. Business Case for Actionable Insights
What can we do if we could determine that a review would be:
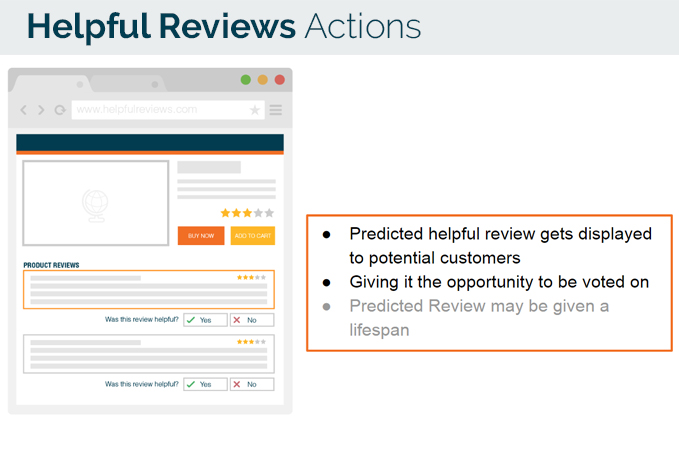
Helpful:
- It could be put in the front of buyers on a product page to help potential buyers make a decision.
- Potential buyers could still vote if that review was helpful to them or not.

Unhelpful:
- The merchant or platform could follow up with the reviewer, seeking recourse or more information.
- Alternative trigger for customer satisfaction issues.
Ultimately, we can provide a better customer experience on and off the platform.
3. The Capstone

3.1 The Dataset
The dataset that was used for this project was from Amazon.com and can be found here I used the Amazon Product Reviews of ‘Tools’ Category.

3.1 Columns of Interest

Before we proceed, we need to understand which columns we would be using as our main features. Those in green, are our main focus features. We need the text data from those columns. For the yellow, we can use them as support features, that may or may not work for our model in predicting if a review is helpful or not.
3.2 The Ground Truth
In the dataset, for each review, there are Total Votes and Helpful Votes.
We accept the ground truth of a review being helpful by considering the amount of helpful or unhelpful votes the review has. An initial approach
Helpful Votes / Total Votes
However we start to realize that there is a fundumental issue with this.
1 Helpful Vote / 1 Total Vote = 100%
99 Helpful Votes / 100 Total Votes = 99%
The problem here is that a review with a single helpful vote (ratio = 1.0) will beat a comment with 99 helpful votes and 1 unhelpful vote (ratio = 0.999), but clearly the latter comment is more likely to be “more helpful.” We needed to take in account of the number of votes.
How do we determine how helpful a review is?
Using Bayesian statistics - read here
We can take into account the number of votes:
1 Helpful Vote / 1 Total Vote = 0.277758
49 Helpful Votes / 50 Total Votes = 0.917
71 Helpful Votes / 100 Total Votes = 0.632
999 Helpful Votes / 1000 Total Votes = 0.996
Now this represents how helpful a review is, in a much better form.
Alas, we need to decide what will our ground truth be This may seem like going one big round, however the bayesian calculation would help further on in the actionable business side to rank and display the reviews according to a score (In this case, we shall call it the Helpfulness Score)
For the project; I have set a hard cut-off point for the ground truth.
1 Helpful Vote / 1 Total Vote = 0.277758 Helpfulness Score
The cut-off for a review to be deemed ‘Helpful’ is that more than 1 person must have voted for it to be ‘Helpful’
IF Helpfulness Score > 0.277758:
Is_Helpful = 1
ELSE
Is_Helpful = 0
3.3 Working Dataset
The original dataset was 1.7M rows. In order for us to build the model, we need to manage our data, for training, testing and predicting on.
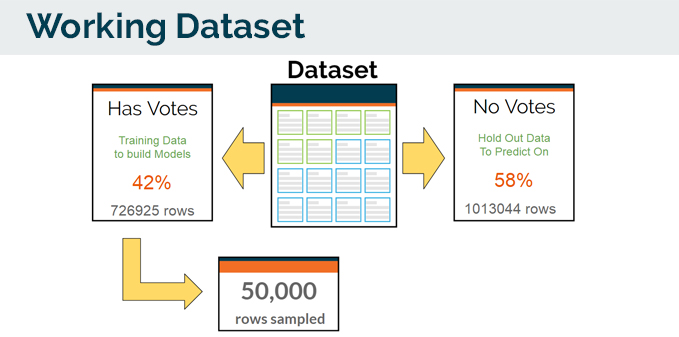
The dataset was split into 2 sets.
- Has Votes - Which we will use for training and building our model. (consist of 42% of the main dataset)
- No Votes - Which is our ‘hold-out’ data to predict on. (consist of 58% of the main dataset)
The logic is that we use the Has Votes, because we have knowledge about it. We predict on the No Votes because these reviews have not been determined if they are Helpful or Not, since they may not even be displayed to the potential buyers.
From the Has Votes set, we sampled 50,000 rows as our working dataset.
4. Before Model Building
Before we go any further, we need to define the approach and metrics that we will use to evaluate our model(s). We are tackling this as a Classification problem. Where we will classify reviews as Is_Helpful = 1 or 0.
- We start off with Data Preparation - cleaning the text data, fixing of HTML embeddings, emoticons, non-UTF-8 characters.
- Next, we proceed with Model Selection.
- Train and Test the model.
- Analyse the results - with respect to the business outcome.
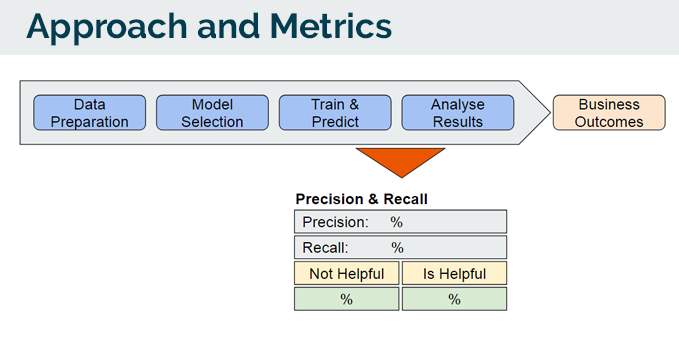
The 2 main metrics that we are looking at would be:
- Precision: When it’s actually ‘Helpful’, how often does it predict ‘Helpful’.
- Recall: When it predicts ‘Helpful’, how often is it correct?
4.1 Baseline model
As this is a binary classification model, we start off with a Logistic Regression model as the baseline model. A pipeline was also built to analyse text features by groups of words and characters together with their frequencies. By iteration, there were 3 main features that contributed to the best logistic regression score.
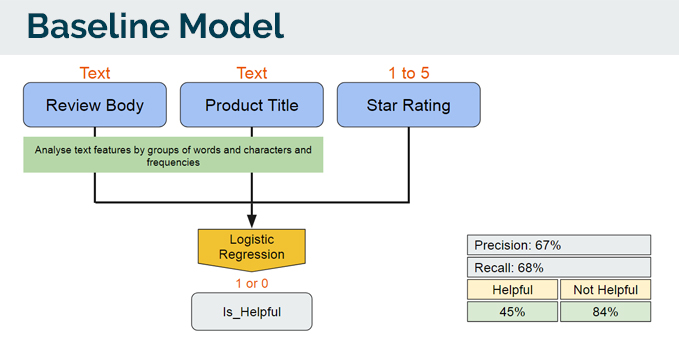
Now that we have a baseline model to start from, we began trying out different models.
4.2 Model Selection

I did a comparison with models that work differently. From Naive Bayes models, Decision Tree models, Boosted Tree models and the Support Vector Classifier
I found that the LinearSVC model could classify the results the best, in accordance to my needs.
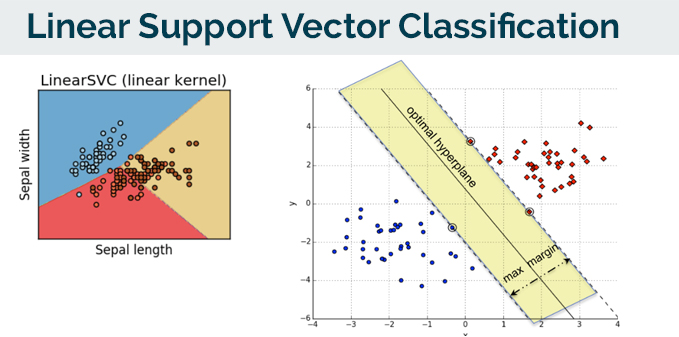 Linear Support Vector Classification
The core concept behind the success and the powerful nature of Support Vector Machines is that of margin maximisation. More specifically, SVMs attempt to build a decision boundary that accurately separates the training samples of different classes by maximising the margin between them. The margin is the (perpendicular) distance from the decision surface to the closest data points of each class.
Linear Support Vector Classification
The core concept behind the success and the powerful nature of Support Vector Machines is that of margin maximisation. More specifically, SVMs attempt to build a decision boundary that accurately separates the training samples of different classes by maximising the margin between them. The margin is the (perpendicular) distance from the decision surface to the closest data points of each class.
4.3. Alternate Model
Given the nature of a this starting off from a NLP (Natural Language Processing) root, I decided to try an alternate approach. Instead of decision boundary approach (LinearSVC), i tried a Recurrent neural network, with a Long Short Term Memory. By this approach, the neural network would be learning via the sequence of words and characters.
This is a simplified way of describing a Recurrent neural network, with a Long Short Term Memory:
- A simple neural network does’nt have any memory. It process information straight through.
- A Recurrent neural network, has some memory. Letting it remember just a little. Remembering and learning (adding information) at the same time.
- A Recurrent neural network with a Long Short Term Memory has the ability to remember more. Therefore learning and remembering and greater capacity.
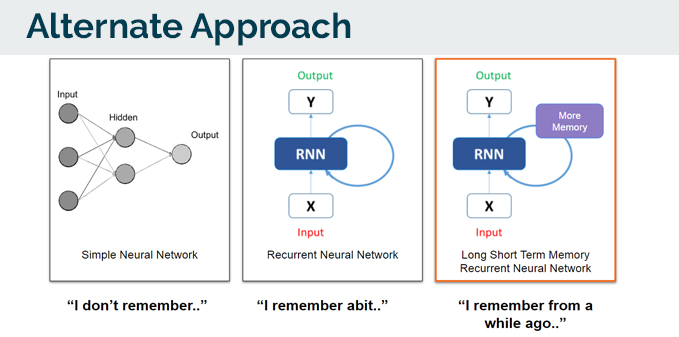
The architecture that I used for the alternate approach, was to create a similar architecture from our LinearSVC model.
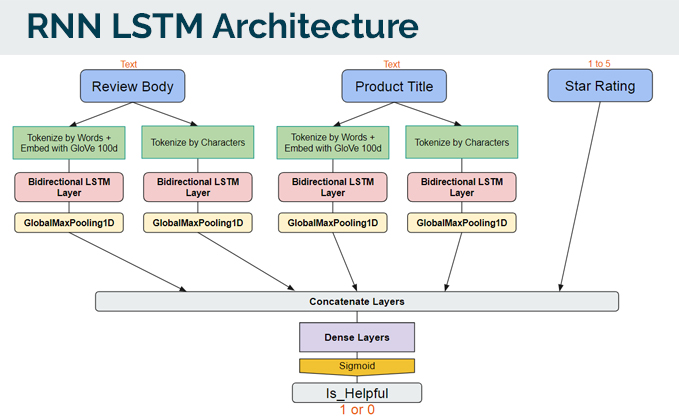
Just a quick note about the above:
- I tried using the GloVE word embeddings at 100d and 300d as well, but the results were the same. Reverting back to 100d was lighter.
- Bidirectional layers allowed the ‘learning’ to go back and forth.
- GlobalMaxPool was used after each LSTM layer to reduce the load before concatenating as the matrix of information (given it was tokenized from text) from the LSTM layer would be large and memory intensive.
Below are the results and the conclusions.
4.4 Model Conclusion & Evaluation

The LinearSVC model trains, and runs faster and less computationally heavy compared to the Recurrent Neural Network. Given that the results are similar, I do have a side conclusion, that if this is the ceiling of results that I am getting, it could possibly mean that i’ve reached the limit of how much information the data (mainly text) can give me.
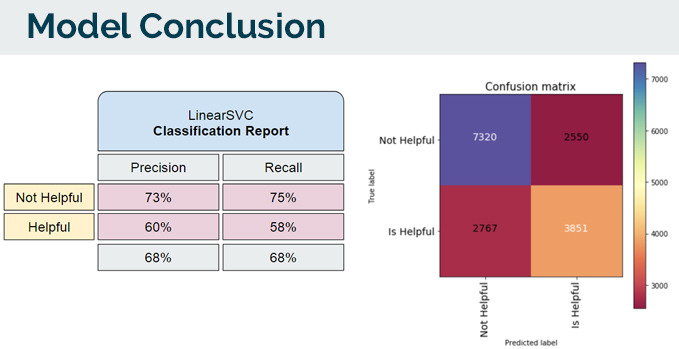
As the meaning of what is helpful or not is perceptive, I am willing to accept the precision scoring. What was more important for me was the percentages % of how many Helpful reviews it managed to classify, as it will have a more direct impact to the business.
5. Risk and Limitations
- Text = Noisy Data:
- It takes iterating and cleaning the text data by removing excessive punctuations, slangs, html embeddings, emoticons, etc.
- Limited Information:
- To the machine, text is always converted and represented as numerical information, traditional methodologies are centered around mathematics (algebra) on numeral representations generated by keyword frequencies.
- Lack of Semantics:
- NLP techniques have not reached the level of a semantic understanding of text.
- Computationally heavy:
- Converting and processing text, even with pipelines, create information that is bloated, hence, it becomes computationally heavy to run models on. For this system, it should not be implemented as a real-time model, however should be a timed-update on the reviews.
6. Next Steps & Improvements
- Collect more data apart from this dataset
- For this model to perform better, in better context, more data such as the product information and descriptions, its life-span on the marketplace etc, may be other predictors I could use to develop a better model, contributing to factors of ‘Helpfulness’.
- Try out different word-embeddings such as FastText
- As compared to the GloVE embeddings, FastText embedding was trained on more informal language which would could have been more ideal for the case of reviews.
- Try out Attention based Neural Network
- Attention based neural network architecture learns to encode a variable-length sequence into a fixed-length vector representation and to decode a given fixed-length vector representation back into a variable-length sequence.
- This may help in the as it learns sentence by sentence, instead of words or characters.
- Dashboard creation and Internal Business tool.
- Model deployment through a web-browser.
7. Final words and future work
The learning journey on this capstone has placed my piqued a very strong interest in NLP. I personally believe that it is a frontier that data science is still a long way to even grasp, let alone ‘complete’. However with that said on the technological data science front, we also must never forget the business application side of the house.
Some future work on this that I am currently exploring:
- Topic Models using LDA and GuidedLDA
- Trying to extract data from GDELT